I’ve been meaning to write this post for a while now, but I never got around to it until today.
Recently, p4plus2 and I released a new SNES project – an inflate algorithm for the SNES. It is capable of decompressing DEFLATE files, and the code is some serious wizardry.
Without further ado, here’s the C3 thread:
http://www.smwcentral.net/?p=viewthread&t=94324.
In here are all the data we found as well as a brief explanation of the format and possible applications.
And the repository link:
https://github.com/Ersanio/SNES-Inflate/
How the idea came to be
Before last C3, I came up with the idea of porting a certain piece of 6502 code to the 65c816, i.e. Super Nintendo Entertainment System. It’s an inflate algorithm written by Piotr Fusik. A few years ago (really), p4plus2 linked me this and I forever stashed it in my “projects to do” list, not really understanding what DEFLATE really does. At least, until very recently.
After my latest semester I’ve learned about graphs and trees and this is exactly what DEFLATE uses – a Huffman Tree. I finally started to understand what DEFLATE really is and found lightweight tools to compress data so now I have things to test. I told p4plus2 about the idea of porting DEFLATE to the SNES and he told me he’s been wanting to do this also, so this became some kind of a collaboration project. Ultimately, I wanted to implement this in Super Mario World as I know that some hack collabs suffered from ROM space issues. There are solutions (such as bankswitching using the SA-1) but solving the problem without any enhancement chips sounded more challenging.
The initial approach
At first, I thought it’d be a matter of “porting an old processor’s opcodes to its successor’s opcodes” which would give it some kind of a performance boost simply by utilizing newly-added opcodes, so you wouldn’t need to “beat around the bush” anymore when you wanted something done. For example, the 6502 doesn’t have stack instructions for the index registers, so you would need to transfer the index registers to A first, then push that using PHA. That’s two steps for a push. In the 65c816, you can simply use PHY or PHX. The first thing I did was making sure the 6502 code worked on the SNES without any optimizations whatsoever. This worked, but then p4plus2 took this project to the next level.
Benchmarking decompression algorithms
p4plus2 has ways to measure code performance on the SNES by using a custom-built SNES debugger. He measured them in “clocks” and we used a compressed GFX00.bin as our test file.
The ported 6502 code used 7415572 clocks (~21 frames). 21 frames might not seem a lot but consider the fact that I want to port this to Super Mario World. Super Mario World can load up to 11 graphics (GFX) files per level, so that’d be roughly 231 frames, give or take a few depending on how well the files are compressed. That’s almost 4 seconds on the level loading screen just for decompressing GFX files. The original SMW decompression algorithm (LC_LZ2) already bothered me to the point of initiating a very successful ASM collab to optimize the LC_LZ2 algorithm.
By p4plus2’s request, I made a bunch of “wrapper” homebrew ROMs which ran various decompression routines on GFX00.bin. I compressed GFX00.bin into LC_LZ2 and LC_LZ3 and ran three decompression algorithms on it: SMW’s original LC_LZ2 decompressor, the highly optimized LC_LZ2 decompressor and the LC_LZ3 decompressor which was based on the highly optimized LC_LZ2 decompressor. p4plus2 benchmarked the ROMs (including the ported 6502 inflate code) and got the following results:
PERFORMANCE: Decompressing GFX00.bin lz2 (original) 1638070 clocks lz2 (optimized) 599616 clocks lz3 1041172 clocks DEFLATE 7415572 clocks
The results kind of scared me. The inflate routine would need a LOT of optimizations. What’s more, p4plus2 recommended that we just start over from scratch so that we would have full control over the code. Making small changes would require us to make many changes in several places in the source code sometimes. To check if this project is worth it at all, I decided to compare DEFLATE to other formats.
Comparing various compression formats
(Admittedly I should’ve done this step before even starting the project. What if the compression format was inferior?)
I compressed all the GFX files of SMW in DEFLATE using zopfli and compared them in other compressed formats in order to see if DEFLATE is a superior compression format or not.
The results were incredible as the compression format beat even LC_LZ3 which is considered an “upgrade” of LC_LZ2:
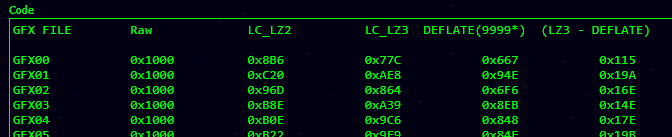
As you can see, DEFLATE saves hundreds of bytes compared to LC_LZ3. When you count all GFX files, DEFLATE saves 0x4A53 bytes total compared to LC_LZ3, which is a HUGE improvement within the context of SNES ROM space. It’s funny to see the compression graphically as well:
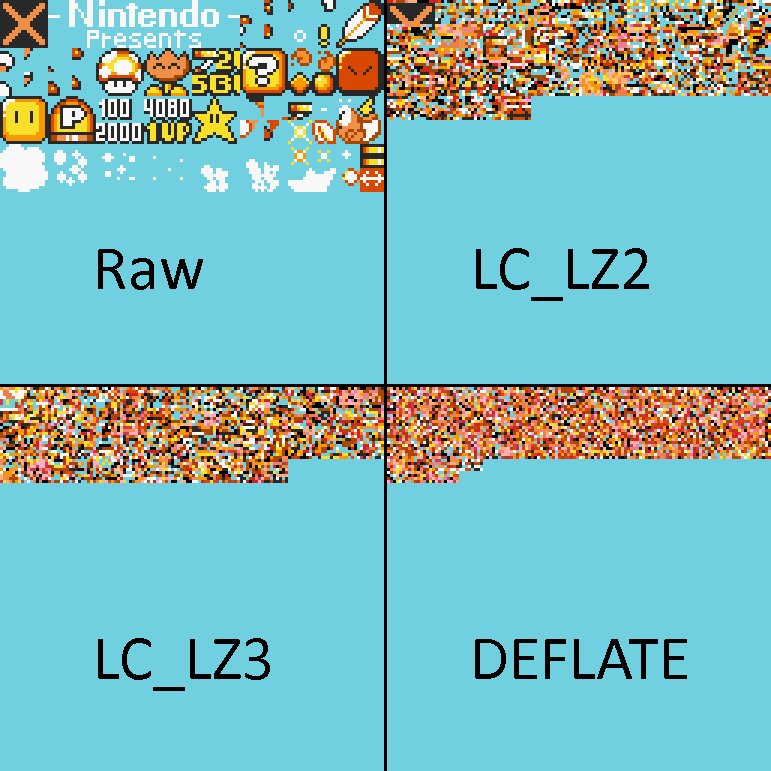
In LC_LZ2 you can still see some of the original graphics just slightly distorted. LC_LZ3 is even more distorted. Then you have DEFLATE which is just… a garbled mess. You can see that every single byte is processed one way or another, thanks to the Huffman coding.
Code with momentum
p4plus2 decided to rewrite the routine from scratch and I applaud his fortitude. As I still have trouble understanding DEFLATE I mostly had a supporting role including finding optimization points in the code, suggesting edits, minor optimizations to his code and pretty much brainstorming with him in general.
At first, p4plus2 wrote the code unoptimized but in such a format that it would be easy to reformat it to an optimized form later. Many existing implementations generated the static tree dynamically in the RAM but we decided to just put the static tree in the ROM. After applying many optimization tricks, we got the code down to 4753212 clocks, from 7695346. It still doesn’t beat the previously mentioned decompression routines, but it’s one hell of an improvement.
Optimization tricks
p4plus2 already had experience with optimizing SNES code as he worked on a few TASbot projects before, which also required insane amounts of optimizing. Most of the optimization was pretty ‘basic’, such as unrolling loops, inline functions rather than function calls, direct copy being DMA’d rather than block moved and switching around branches so that they are taken less often. We also removed some obsolete opcodes (such as CLC/SEC) which required a bit of code analyzing and experimenting.
The most interesting optimization tricks used are messing around with the stack pointer and honestly I think that’s entering black magic territory. Take a look at this code:
An inexperienced ASMer would immediately notice that there’s a pull without a push. That would cause the program to crash! …But there are strings attached. First of all, this entire code is in 16-bit mode as mentioned earlier. Second, code_length_codes is a table with 16-bit values and the stack pointer is set to that. As the stack pointer is a 16-bit value, it can also point to bank 00 of the ROM. Finally, PLX increases the stack pointer by +2 (as we’re in 16-bit mode). As a result, this code reads out the bytes and stores them in the RAM addresses defined in the code_length_codes table. Every PLX is basically shorthand for a bunch of instructions which read out code_length_codes, transferring it to the X register, then increasing the code_length_codes index by 2. This is quite the extreme (and clever!) optimization but it was possible as the stack wasn’t used in this area.
The second extreme optimization also involves the stack pointer register as well as a bit of the direct page register. There’s no stack pulling magic here, however.
This routine is the main bottleneck of inflate. It’s called hundreds of times so it only makes sense to optimize this routine as much as we can, even if it means shaving off 1 cycle at a time.
First, we used the direct page register to clear the accumulator because it’s always nice to assume the direct page register is set to 0000h. Then we basically used the stack register for scratch RAM purposes. It’s faster than using actual scratch RAM. A TCS/TSC takes two cycles while doing an “LDA $dp” or “STA $dp” in 16-bit mode takes four. Also, a TDC takes two cycles while an “LDA #$0000” takes three. Because the routine gets called hundreds of times, the optimizations are pretty much hundreds of cycles!
Future projects
With the recent developments on the SA-1 chip thanks to Vitor Vilela and his SA-1 pack, the possibility of an SA-1 port is very real. This would mean that the inflate code could run even faster with minimal modifications to the code itself. What’s more, inflate could be optimized even more with a barrel shifter and SA-1 just happens to have one.
Personally I would also like to make a SuperFX port of inflate so that the Yoshi’s Island community would be able to benefit from the compression, although compression tests show that LC_LZ16’s compression is superior in some cases. I don’t think this will hold me back, though. As I don’t fully understand the DEFLATE format yet, I plan to write inflate in C# first to grasp the essentials of the decompression algorithm. After I truly understand how inflate works, I could give the SuperFX version a serious attempt. I know that if I were to write one right now, with my current knowledge, all I would do is take the SNES code and port it to SuperFX like some kind of a tool.
Closing words
This is possibly the grandest SMW hacking ASM projects I’ve worked on so far. I’m really glad that me and p4plus2 worked on this project together. If I tried this solo, I would’ve simply ported the 6502 code and called it a day (but the project technically would’ve been successful)!
There were so many steps involved. It wasn’t a matter of “oh I got the idea to code LevelASM, I’ll just code it real quick” but it actually required careful planning, experimenting and a solid understanding of the algorithm.
In my opinion, this project is very revolutionary for SNES ROM hacking in general and I hope that other people will find even more optimization points. Furthermore, I hope that FuSoYa officially implements this in Lunar Magic once there’s a working SA-1 port.
Thanks to p4plus2, I learned new (optimization) tricks for the SNES. I also confirmed my suspicions that he is an actual wizard.